I hang out a lot in the Serverless forum and Gitter - I just like talking about this new-fangled FaaS (Functions-as-a-Service) thing. A common misconception that keeps coming up is that it's not an appropriate choice for things that use a database connection because you have to create a database connection for every request you receive, and that's just not the case!
Containers
In case you didn't get the memo, AWS Lambda uses containerisation to run your code on Lambda. Knowing this, we can optimise our code to take advantage of the deployment model for the greatest efficiencies.
Scope
Scope refers to where (and for how long) variables can be accessed in our programs. By specifically creating variables in and outside of our handler function we can share variables (like database connections) between requests (with caveats, see below). The link above clearly defines it:
Any declarations in your Lambda function code (outside the handler code, see Programming Model) remains initialised, providing additional optimization when the function is invoked again. For example, if your Lambda function establishes a database connection, instead of reestablishing the connection, the original connection is used in subsequent invocations. You can add logic in your code to check if a connection already exists before creating one.
Deciding where your variables should be instantiated is a balancing act; The more you put outside your function handler the quicker your warm execution will be, but the slower your cold execution will be (see below for more on warm and cold functions). The more you put inside your function the simpler your run-time environment will be to reason about (in the event of bugs).
Example
Here's a simple and contrived example connecting to a database to get user data:
const pg = require('pg');
const client = new pg.Client('postgres://myrds:5432/dbname');
client.connect();
exports.handler = (event, context, cb) => {
client.query('SELECT * FROM users WHERE ', (err, users) => {
// Do stuff with users
cb(null); // Finish the function cleanly
});
};
In this example, my database client connection is defined outside the handler, and so is available between invocations of my Lambda Function. The users data is only defined and scoped within my handler, so cannot leak between invocations.
Here's the same diagram with the scope highlighted:
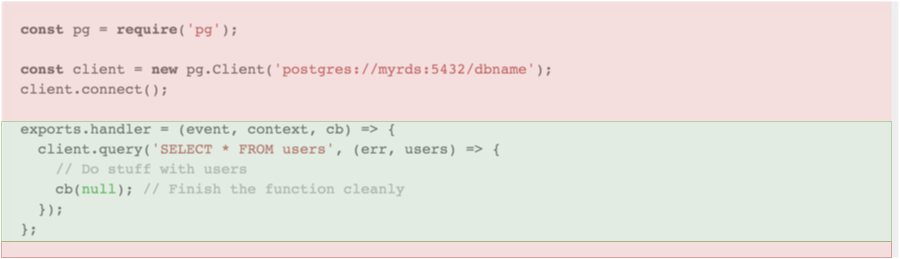
The red sections are shared, and the green section is per-invocation. It should be noted that the scope has nothing to do with the ordering of your code - the code after the handler function is part of the parent scope because it's outside the handler function, as indicated above.
Warm vs Cold
When talking about Lambda Functions, you'll often hear talk of warm and cold functions. This refers to whether or not the function has been "recently" used or not (for some definition of "recent") and impacts how long the function will take to respond.
If a function is called, it is "warmed" by being loaded in to memory. This loading takes additional time, and is why you first invocation of a function after a deploy or a long period of time takes longer (and you charged more for it). You can see the exact invocation times in the CloudWatch section of the AWS Console.
After a period of inactivity the function's container goes "cold" and it is remove from active memory. I haven't seen exactly what the period of inactivity needs to be, and AWS may even change that number on the fly (i.e. if other containers were busy). It's worth noting that even an active container will go cold eventually, as detailed by these guys.
A sure way to force a refresh of your container is to re-deploy your function - you only need to update the function's description get a new container allocated.
There's a few more hints around "freezing" and "thawing" your function containers in this AWS blog post that are good to know.
Caveats
In this scenario I've specifically defined client so that it can be re-used between requests, but keep in mind that for most variables in your application it is not what you want to do. You have to be very careful not to let any of your function state unintentionally persist or "leak" between calls. If your query handler did anything that put data (which would probably be user-specific) in the parent scope (i.e. the red section) then it might be available to requests by other users.
Data leakage this way is an example of why global state is bad because it makes programming state unpredictable, and that makes it difficult to debug and fix.
Other Languages
My example uses NodeJs, because that's my preferred language, but the principal applies to all of the supported languages. Make sure that you define you connection outside of the handler function that you specify in your Lambda Function's configuration, and it will be kept around between (warm) requests to your function.