Recently I've been working with Step Functions in my day-to-day work, as well as in my personal projects, and I decided to write this post as a way of articulating the ins-and-outs of Step Functions I've learnt while using them.
It helps that a few new features have been added to Step Functions recently, which further improve their functionality and value proposition.
I wrote most of this article before seeing the official recommendations in the documentation; while there's some overlap, I think the documentation could do with an update to encompass the new features.
State Machines
Since AWS Step Functions are really just state machines, it's a good idea to have a clear picture about what they are when you're using Step Functions (from Wiktionary):
state machine
n. A formalism for describing computation, consisting of a set of states and a transition function describing when to move from one state to another.
This is a pretty academic way of saying that state machines force you to think about the different states your application can be in, and how it transitions between those states; this is where I see most developers and teams getting value out of AWS Step Functions.
Thinking about your application in this way takes time and practice, and you can make that process easier by following these practices
- Set up Your Payload
- Handle Exceptions if Needed
- Set Timeouts
- Avoid Waits
- Avoid Activities
- Nest Step Functions
- Use Dynamic Parallelism Sparingly
- Monitoring
Set up Your Payload
I like to have an initialisation state that collects any additional parameters and configuration that aren't already supplied in the triggering execution payload. This might be getting values out of SM Parameter Store, database connection strings, etc. I then include these in the output of this initial state, so that they can be used by following states:
I use this pattern because it follows functional programming patterns that I think are beneficial: the behaviour of your code should be determined by their inputs, not on other (less visible) parameters or settings. This approach works well with Lambda Task states, because I can easily test my functions being called with a specific payload.
By setting all of your required values in an initial state, and then passing that through your state machine, you get a clean and clear picture of the inputs that your states depend on. This has the nice effect that all of the information you need to troubleshoot a failed state is at hand in the Input of your state.
The exception to this is secrets. I wouldn't want to be passing secrets around as the payload is recorded in many places in plaintext; instead use a reference to where the secret is located, or handle them out-of-band.
Handle Exceptions if Needed
Handle state exceptions if you need to clean up partially-completed activities, or perhaps report to an external source like email, Slack, etc.
If you don't need to do any cleanup, then just let the Lambda error; the Step Function interface will show you clearly which state failed, and even show you Lambda exceptions in the Step Functions console (with a link to the Lambda console and CloudWatch Logs console), which makes troubleshooting quick and easy.
Start by catching States.ALL in your ErrorEquals, and add more explicit entries to your Catch property as needed. There's an error handling demo in the documentation you can use to see it in action.
Set Timeouts
Forgetting to set sensible timeouts is something I've seen many developers (including myself) fall prey to. If there's an obvious and sensible limit to how long something should reasonably run, then capture that explicitly in the TimeoutSeconds property of your state.
While this probably won't save you much trouble during development, it will save you when you've deployed your Step Function to production and you're no longer watching it's every execution. This should be similar to how you treat your Lambda functions already (you ARE setting reasonable timeouts on your Lambda functions, aren't you?!).
Avoid Waits
Well, avoid static wait states; If you're just going to set a static value in seconds, you're probably just working around a downstream limitation (i.e. by polling).
This is probably the recommendation on this list I ignore the most myself, but I don't feel good about it when I do.
Remember that you can wait a dynamic amount of time by using SecondsPath to reference a value, or to a specific time using TimestampPath and the JSON path syntax (e.g. $.path.to.my.value). By using these values and setting the value dynamically, you can implement back-off timing as well.
Avoid Activities
Activities used to be the only way to do long-running, out-of-band work that didn't fit in to a Step Function service integration.
This is no longer the case now that we have the callback pattern: Start a task, and have the worker callback to the Step Function (with the task token) when it's completed; no polling, no waiting.
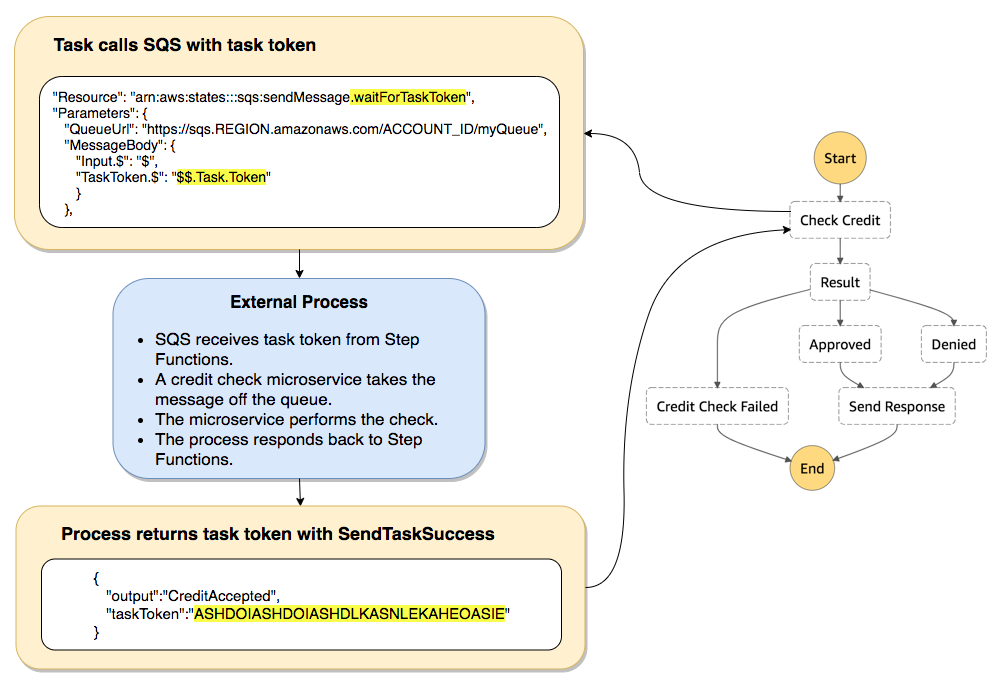
There's of the callback pattern in the documentation, and in the Sample Projects if you create a Step Function through the console:

Nest Step Functions
Another one of the recently released features is the ability for a Step Function to have a service integration with Step Functions; meta, I know.
This is great because it allows you to encapsulate and "abstract away" related (but complex) workflows in their own state machine.
Use Dynamic Parallelism Sparingly
While I haven't had a chance to use to use the just-announced dynamic parallelism, I will be using it with care when I do.
New – Step Functions Support for Dynamic Parallelism – this was probably the most requested feature for Step Functions! It was fun writing this post, the new Map state type is unblocking many use cases https://t.co/a4IyHvJuFi #AWS #Serverless #Workflow pic.twitter.com/MVWRtk80Gt
— Danilo Poccia @ Seattle (@danilop) September 18, 2019
While it might be the most requested feature, I can definitely see ways that this functionality can go wrong. Part of the benefit I see in Step Functions is that it limits you things you can explicitly declare up-front; sometimes less is more. Hopefully, the built-in limitations of the states language will help protect users (i.e. ME) from any run-away scenarios...
Monitoring
You should keep an eye on how your Step Functions run. A CloudWatch Dashboard with the following recommended metrics would be a good place to start:
- ExecutionsStarted
- ExecutionsFailed
- ExecutionsAborted
- ExecutionsTimedOut
- LambdaFunctionsStarted
- LambdaFunctionsTimedOut
These basic metrics will highlight if your executions start behaving strangely, without taking a long time to think about or configure.
Conclusion
These are recommendations, that you can - and should - ignore in the right situations.
That being said, if you don't have a reason to ignore them I strongly recommend you follow them, as they will help you when things go wrong in your state machines. As always, the Amazon States Language Specification is your friend.