
Serverless solutions is can be incredibly cheap due to their event-based nature - if your system isn't working, you pay barely anything for it. Generous free usage quotas applied by AWS and the other cloud vendors also help with this. But if you're not careful, serverless can still result in some nasty surprises when it comes to costs.
While there's been plenty written on basic things like function sizing (and there's even tools to help you do it), I wanted to talk about some of the less-than-ideal situations you can find yourself in, mainly due to the fact that Distributed Systems are Hard...
Limit Concurrency
By default each AWS Lambda function can be run 1,000 times at once (but the actual bust up to this depends your region). This makes it an incredibly scalable and powerful option, when used for the right thing; when doing The Wrong Thing, this concurrency can bite you by parallelising your failures, enabling you to rack up expenses 1,000 times faster than you thought!
Many back-end functions have no good reason to be running concurrently. If you have a function that should (under normal operating conditions) never be run more than once at a time, make it official and set the ReservedConcurrentExecutions for the function to 1 in your function configuration. If you do hit the limit your callers will receive a throttling error (429 status code), which you should decide explicitly how to handle in your upstream systems (e.g. ideally by backing-off or failing loudly).
Break Loops
A common error cause I've seen in distributed systems is malformed or unexpected messages being passed between systems, causing retry loops. Just like with concurrency, the platform is trying to do the "right thing" by retrying; when this results in errors being repeated forever, it's not great. You should build short-circuits in to your system, so that you can break out of harmful loops.
SQS and Lambda
Here's one I ran in to recently: If a Lambda listening to an SQS queue can't process the message, it returns it to the queue... and then gets given it back again again!
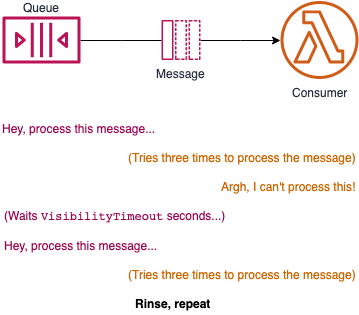
If you set an SQS DLQs on an SQS queue that Lambda is consuming from, it will send any messages that the Lambdas cannot process to the DLQ. Don't be confused with the Lambda's DLQ; if you only set the DLQ on the Lambda itself, they will continue to pull the bad message from the queue (and then put it in their DLQ). The fix is to set the DLQ on the SQS queue itself:
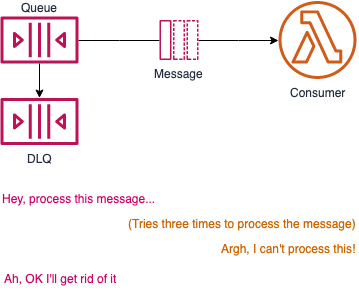
Obviously setting DLQs on your Lambda's directly is still a great idea in many cases; just be mindful this won't stop the upstream service from trying to send (potentially bad) events again.
Event Loops
A classic new-to-serverless example is related to loops: an S3 bucket event (or any other Lambda event source) triggers a function that then writes back to the same source, causing an infinite loop. Don't laugh, it's happened to many people.
On principal I always limit my S3 buckets to being either sources or targets (given buckets themselves cost nothing) for activities. There are middleware libraries that can help with some scenarios like this, but it's definitely not a sure-fix.
Step Functions
Step Functions are obviously a great piece of serverless applications, just be sure to think about the states where you application may want to retry. I've seen many developers (myself included) new to state machines think only about the "happy path" of execution.
In Step Functions, you can use Retriers to explicitly determine if, when, and how you should retry - and back-off from - failures.
Throttling
Using messages and queues as a way to decouple your functions is generally a good architectural practice to use; it can also protect you from some cost surprises.
Kinesis is a good solution when you want to effectively throttle your consumption of messages, which means you can put an upper limit on

In this case the stream takes care of concurrency, limiting your function's executions to one per shard.
Keep in mind that the various messaging services have very different cost profiles. Yan's Cui post on serverless bills has a great example comparing SNS and Kinesis at different levels of usage - TL;DR is SNS is great value a low volumes, but becomes expensive at high volumes; Kinesis is the inverse.
API Gateway is another key serverless component on AWS, that is relatively expensive at high volumes. Using a usage plan can give you piece of mind, by putting a roof on the total cost you're exposed to.
Monitoring
In the elastic cloud, pay-as-you-go world that serverless lives in, cost is another part of your operational metrics, just like CPU and memory usage were in an on-premises world in the past.
While you can do a lot to automate the monitoring and alerting for many of the common issues that come up, in new and novel situations, your alerting might not be able to recognise an issue until it's too late. Creating dashboards to visually monitor for anomalies is a relatively low-effort way to enable your humans (assuming someone is actually going to look at them; if not, then don't bother with them).
Billing alerts
This is a basic technique that many people seem to forget, it's still something that's worth doing even if you've followed all the steps above.
When all your best efforts fail, and your system ends up in an expensive error state, you can trust that AWS will still send you a bill for what you've used! Setting a billing alert also serve as a catch-all for other scenarios that you'd want to know about (e.g. being attacked in a way that causes you to consume resources).
Conclusion
There are more and more good examples of approaches to mitigating and reducing your servleress costs, but the key takeaway should be this: Cost optimization is not something that will happen by accident in the cloud, you need to make it happen.
Photo by Hafidh Satyanto on Unsplash